
认识KafKa
什么是KafKa
kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
Kafka的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
在Kafka有几个比较重要的概念:
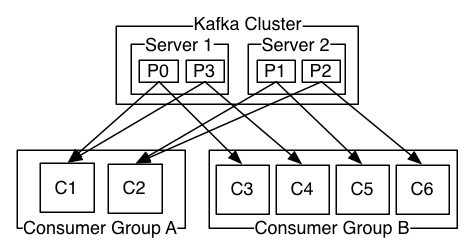
broker
用于标识每一个Kafka服务,当然同一台服务器上可以开多个broker,只要他们的broker id不相同即可
Topic
消息主题,从逻辑上区分不同的消息类型
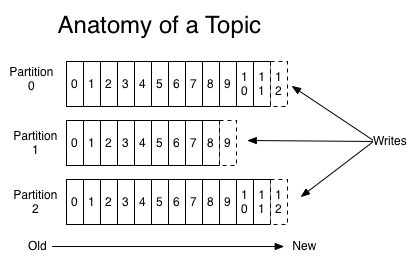
Partition
用于存放消息的队列,存放的消息都是有序的,同一主题可以分多个partition,如分多个partiton时,同样会以如partition1存放1,3,5消息,partition2存放2,4,6消息。
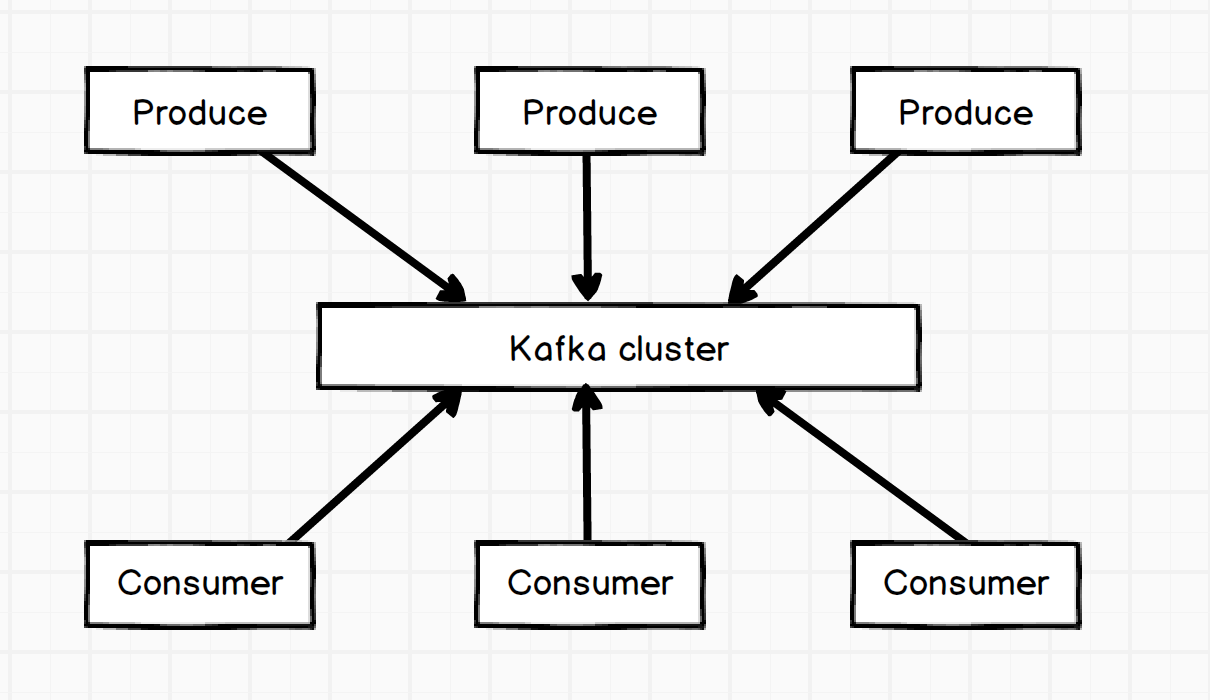
Produce
消息生产者,生产消息,可指定向哪个topic,topic哪个分区中生成消息。
Consumer
消息消费者,消费消息,同一消息只能被同一个consumer group中的consumer所消费。consumer是通过offset进行标识消息被消费的位置。当然consumer的个数取决于此topic所划分的partition,如同一group中的consumer个数大于partition的个数,多出的consumer将不会处理消息。
分布式搭建KafKa
服务器资源:
| 服务器名称 | 操作系统 | IP地址 |
|---|---|---|
| Server-01 | Centeos 6.5 | 172.16.128.144 |
| Server-02 | Centeos 6.5 | 172.16.128.145 |
| Server-03 | Centeos 6.5 | 172.16.128.146 |
在每台服务器上提前安装JDK 1.8
使用命令行Java -version查看是否成功

Kafka是通过Zookeeper进行管理群集,在每台服务器上先安装zookeeper。
搭建Zookeeper
zookeeper下载:
1 | wget https://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.3.6/zookeeper-3.3.6.tar.gz |
解压zookeeper:
1 | tar -xvf zookeeper-3.3.6.tar.gz |
修改配置文件:
1 | cp conf/zoo_sample.cfg conf/zoo.cfg |
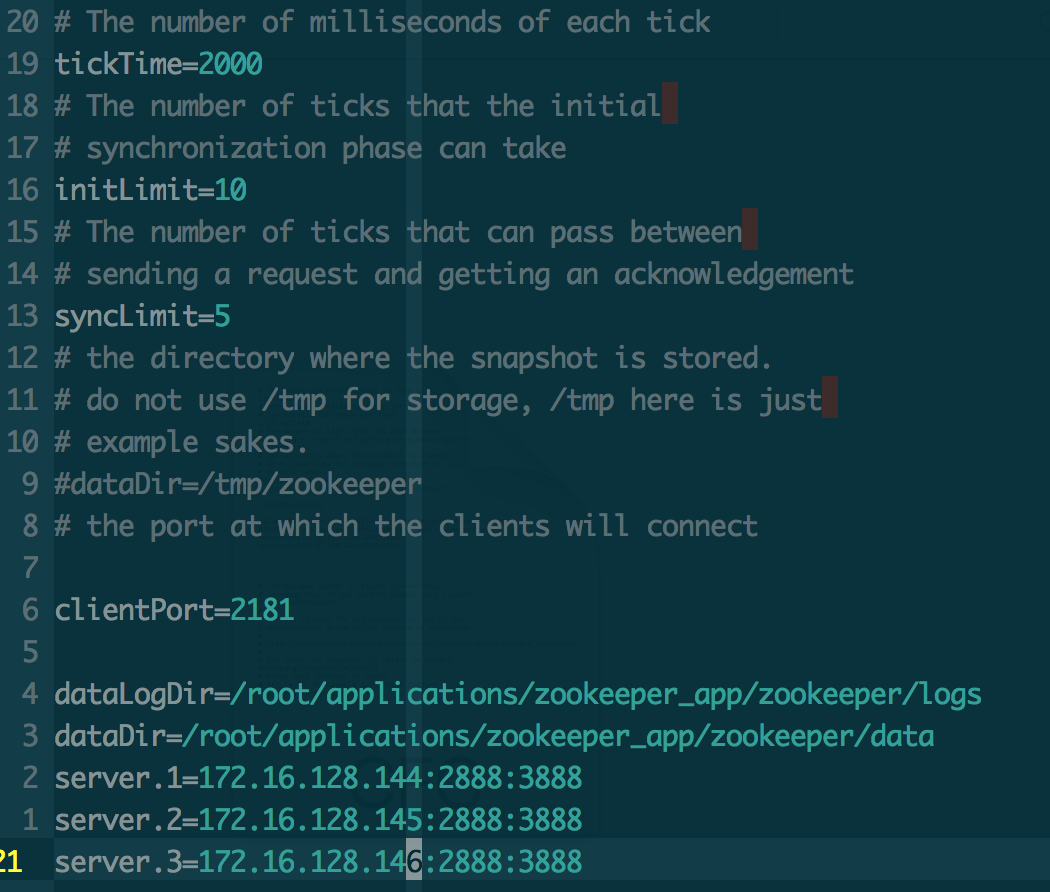
配置文件参数说明:
tickTime这个时间是作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳。
initLimit这个配置项是用来配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20秒。
syncLimit这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
dataDir顾名思义就是zookeeper保存数据的目录,默认情况下zookeeper将写数据的日志文件也保存在这个目录里;
clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
server.A=B:C:D中的A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
创建ServerID标识:
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。
这个文件里面有一个数据就是A的值(该A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路径中创建myid文件。
在172.16.128.144服务器上创建myid文件,并设置为1,同时与zoo.cfg文件里面的server.1对应,如下:
1 | echo "1" > /root/applicaton/zookeeper_app/zookeeper/data/myid |
将上述配置好的文件通scp命令分别复制到server-02,server-03上面
1 | scp /root/application/zookeeper_app/zookeeper root@172.16.128.145 /root/application/zookeeper_app/ |
启动各服务器上的zookeeper:
1 | ../zookeeper/bin/zkServer.sh start & |
查看zookeeper状态:
1 | ../zookeeper/bin/zkServer.sh status |
查看状态会看到其中一台服务器的mode为leader,其他两台为follower

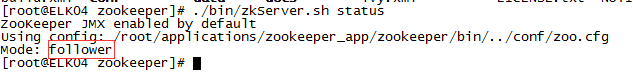
搭建Kafka
kafka下载:
1 | wget https://www.apache.org/dyn/closer.cgi?path=/kafka/0.11.0.0/kafka_2.11-0.11.0.0.tgz |
解压kafka:
1 | tar -xvf kafka_2.11-0.11.0.0.tgz |
修改配置文件:
1 | vim config/server.properties |
配置文件参数说明:
broker.id broker唯一标识
listeners kafka监听IP及安全方式
log.dirs 日志存储
num.partitions 创建topic时默认partition数量
zookeeper.connect zookeeper服务器地址
启动各服务器kafka:
1 | ../kafka/bin/kafka-server-start.sh ../config/server.properties & |
查看kafka状态可以通过命令行执行jps或pa -aux 或netstat -ntlp
利用netstat -ntlp会看服务器监听的9092接口。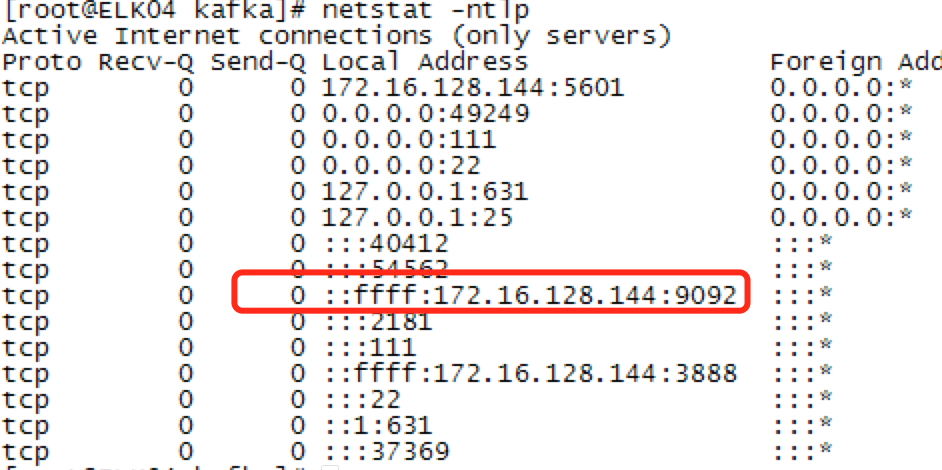
使用KafKa
Kafka Console
topic
创建
1 | ./bin/kafka-topics.sh --zookeeper 172.16.128.144:2181,172.16.128.145:2181,172.16.128.146:2181 --create --topic my-test-topic --partitions 5 --replication-factor 1 |
查看
1 | ../kafka/bin/kafka-topic --list --zookeeper 172.16.128.144:9092 |

Produce
1 | ./bin/kafka-console-producer.sh --topic my-test-topic --broker-list 172.16.128.144:9092,172.16.128.145:9092,172.16.128.146:9092 |
Consumer
1 | ./bin/kafka-console-consumer.sh --bootstrap-server 172.16.128.144:9092,172.16.128.145:9092,172.16.128.146:9092 --topic my-test-topic --from-beginning |
Native JAVA API
创建Java Maven项目.
在Pom文件中引入”kafka-clients” jar包
1 | <dependency> |
Produce
1 | private static String topic = "my-test-topic"; |
Consumer
1 | private static String topic = "my-test-topic"; |
Spring boot Kafka
Spring boot Kafka是由spring对kafka操作的一种封装,方便进行对kafka操作(Spring对Kafka的操作有spring-kaka和spring-integration-kafka,示例以spring-kafka操作kafka)。
创建spring boot项目。
在pom文件内引入”spring-kafka”jar
1 | <properties> |
配置spring application.yml
1 | spring: |
Produce
添加produce配置java文件及处理文件。
SenderConfig.java
1 |
|
Sender.java
1 |
|
Consumer
添加consumer配置java文件及处理文件。
ReceiverConfig.java
1 |
|
Receiver.java
1 |
|
总结
到此kafka的搭建到使用都已结束,在消费kafka消息时,建议使用spring boot + spring kafka。
由于spring boot打包部署比较方便,同一台机器上可以开多个spring boot也就是开多个进程的consumer。
如不想开多个进程处理,在spring kafka 中@KafkaListener注解可针对不同的topic,不同的partition消费,也可开不同的线程进行消费kafka。
kafka还有很多需要学习的地方,如:kafka-stream,topic的管理,topic的消息分布情况,查看当前有多少个consumer group,每个consumer的offset是多少等等。
